Accélérez la prise de décisions éclairées avec une IA conçue pour la chaîne d'approvisionnement
Nos solutions d’IA prédictive, générative et agentique s’appuient sur des décennies d’innovation dans la chaîne d’approvisionnement et d’expertise en IA pour transformer les données brutes en prédictions et conseils qui aident vos équipes à gérer cette complexité.
Démystifier l'IA pour les leaders de la chaîne d'approvisionnement
Les avantages de l'intelligence artificielle pour les responsables de la chaîne d'approvisionnement sont évidents, mais sa mise en œuvre n'est pas toujours aussi simple. Découvrez pourquoi (et comment) votre entreprise devrait donner la priorité aux solutions d'IA dès maintenant.
Réorganiser pour l'IA : comment les leaders de la chaîne d'approvisionnement doivent s'adapter
90% of supply chain leaders are currently executing a reorganization or will do so in the next 12 months. Many are preparing their teams for AI-driven supply chain technology, but how should they adapt and reorganize for an AI-first future?
DHL économise 7 % sur les coûts de transport grâce à une meilleure optimisation des véhicules et des arrêts avec Blue Yonder Network Design
Groupe Carlsberg
Carlsberg explique comment l'entreprise adopte une approche numérique en priorité grâce à la gestion des transports de Blue Yonder, à la stratégie « Zero & Beyond » de l'entreprise et plus encore.
Walgreens
La gestion des commandes basée sur l'IA de Blue Yonder fournit la "magie" derrière la promesse de commandes clients en 30 minutes de Walgreen.
Comment la planification basée sur l'IA améliorera les performances de votre chaîne d'approvisionnement ?
L'extrême volatilité, les pénuries de stocks et la surcharge de données sont tous des défis auxquels les entreprises sont confrontées en matière de planification de la chaîne d'approvisionnement. Les capacités de planification basées sur l'IA peuvent relever ces défis en améliorant la prise de décision, l'agilité et la collaboration entre les différentes fonctions de la chaîne d'approvisionnement.
2026 Supply Chain Compass: How Supply Chain leaders are navigating complexity
The Supply Chain Compass 2026 report surveys nearly 700 supply chain leaders, exploring how they are navigating a rapidly evolving landscape shaped by AI, disruption, and rising expectations. While nearly half express strong optimism about the future, the report reveals that this confidence is driven by greater visibility, stronger technology adoption, and more integrated, data-driven supply chain strategies.
Dépasser le cloisonnement : évoluer vers une chaîne d'approvisionnement d'entreprise
Incisiv explore la transformation significative en cours dans les chaînes d'approvisionnement modernes, détaillant le passage de processus fragmentés et de solutions ponctuelles à des plateformes plus agiles et à des flux de travail collaboratifs. Cette évolution répond à des problèmes systémiques tels que le manque de flexibilité et la communication déconnectée, améliorant ainsi la réactivité, la durabilité et la rentabilité de la chaîne d’approvisionnement.
L'erreur moyenne absolue en pourcentage (MAPE) a fait son temps et doit maintenant être retirée.
Blog
L'erreur moyenne absolue en pourcentage (MAPE) a fait son temps et doit maintenant être retirée.
L'erreur moyenne absolue en pourcentage (MAPE) a fait son temps et doit maintenant être retirée.
Malte Tichy, 4 minute de lecture
Selon Gartner (2018 Gartner Sales & Operations Planning Success Survey), la mesure d'évaluation la plus populaire pour les prévisions dans le cadre de la planification des ventes et des opérations est l'erreur absolue moyenne en pourcentage (MAPE). Cela doit changer. Les prévisions modernes portent sur de petites quantités à un niveau désagrégé, par exemple produit-lieu-jour. Pour des prévisions aussi granulaires, les valeurs MAPE sont extrêmement difficiles à évaluer et ne constituent donc pas des indicateurs utiles de la qualité des prévisions. Le MAPE induit également les utilisateurs en erreur en exagérant certains problèmes et en en dissimulant d'autres, ce qui les incite à choisir des prévisions systématiquement biaisées. Les situations dans lesquelles le MAPE est adapté sont de plus en plus rares. Il ne s'agit pas d'une théorie aride : Nous simulons un supermarché qui s'appuie sur une valeur prévisionnelle optimisée par MAPE pour le réapprovisionnement. Les sous-stocks et les surstocks dans les magasins à vente rapide et à vente lente poussent rapidement le magasin à la faillite.
Lorsque les erreurs absolues et relatives se contredisent, à qui devons-nous faire confiance ?
Vous aviez prévu une demande de 7,2 pommes et 9 ont finalement été vendues. Vous aviez prévu 91,8 bouteilles d'eau et 108 ont été vendues. Vous aviez prévu 1,9 boîte de thon et une a été vendue. Comment jugez-vous ces erreurs de prévision ? Une approche simple consiste à calculer l'écart absolu de la prédiction par rapport à la réalité et à le diviser par cette dernière, c'est-à-dire l'erreur absolue relative, éventuellement sous la forme d'un pourcentage(erreur absolue en pourcentage, APE). Cela semble beaucoup plus compliqué que cela ne l'est : L'utilisation de l'APE comme première solution pour "l'évaluation de la qualité des prévisions" est tout à fait typique. Pour les trois exemples, vous obtenez des APE apparemment modérés de 20% (=|7.2-9|/7.2), modeste 15% (=|91.8-108|/108) et 90% (=|1,9-1|/1), respectivement. Le MAPE, pourcentage absolu moyen d'erreur, est la moyenne arithmétique de ces trois pourcentages et s'élève à 41,67%. Ces pourcentages d'erreur indiquent que la prévision sur le thon est moins bonne que celle sur les pommes, et que la prévision sur les bouteilles est plus performante que les autres. Mais cela reflète-t-il vraiment la qualité des prévisions ? Regardez à nouveau le début de cette section - la grande différence absolue entre les bouteilles d'eau prévues et réelles est inquiétante, et sa petite erreur relative ne peut pas vraiment vous rassurer. D'autre part, l'erreur de 90% sur le thon pourrait être due au hasard (à la malchance) - il ne s'agit que d'un seul élément. Devriez-vous taire votre intuition et vous fier aveuglément aux APE ? Par conséquent, devriez-vous réviser les prévisions concernant le thon et laisser les prévisions concernant l'eau en l'état ? Si une autre prévision est émise, avec un MAPE global de seulement 30%, cette nouvelle prévision est-elle nécessairement meilleure ?
Bien entendu, je ne vous demanderai jamais sérieusement d'ignorer votre jugement humain ! Ce paradoxe désagréable est résolu ci-dessous : Le MAPE n'est pas adapté aux prévisions probabilistes modernes au niveau granulaire (c'est-à-dire au niveau du jour de l'emplacement du produit, où de "petits" nombres ou même "0" peuvent se produire), en raison de plusieurs problèmes intolérables et insolubles. Le MAPE d'une prévision ne nous renseigne pas sur la qualité de cette prévision, mais sur le comportement étrange de l'APE.
Ignorer consciemment l'échelle : Quand les erreurs de pourcentage peuvent avoir un sens
Avant d'aborder les prévisions granulaires dans le commerce de détail (au niveau du produit, de l'emplacement et du jour), supposons qu'il faille prévoir une quantité beaucoup plus importante : Le produit intérieur brut (PIB) annuel des pays, mesuré en dollars américains. Ces prévisions pourraient être utilisées pour définir des politiques pour des pays entiers, et ces politiques devraient être applicables de la même manière à des pays de tailles différentes. Il est donc juste de pondérer chaque pays de la même manière dans ce cas d'utilisation : Une erreur de 5% sur le PIB des États-Unis (environ 25 000 milliards de dollars) fait autant de mal qu'une erreur de 5% sur le PIB de Tuvalu (environ 66 millions de dollars, soit 380 000 fois moins que le PIB des États-Unis). L'erreur absolue en pourcentage (APE) prend ici tout son sens : Le PIB réel n'est jamais proche de 0 (ce qui causerait un terrible mal de tête en le divisant, j'y reviendrai plus loin), et l'objectif des prévisions n'est pas d'obtenir le PIB global de la planète, mais d'en être le plus proche possible pour chaque pays, sur des échelles allant de quelques millions à quelques milliers de milliards. Minimiser l'erreur absolue totale du modèle (c'est-à-dire (erreur en US$, pas en pourcentage) met en avant les plus grandes économies et néglige les plus petites. Il ne pondère pas chaque pays de la même manière, mais en fonction de sa puissance économique. Un modèle avec une belle erreur de 3% sur le PIB américain et une erreur inacceptable de 200% sur le PIB de Tuvalu semblerait "meilleur" qu'un modèle avec une erreur de 4% sur le PIB américain et une erreur de 10% sur le PIB de Tuvalu en termes absolus de dollars. Le MAPE, quant à lui, incite à utiliser cette dernière prévision, qui sacrifie une grande partie de la précision absolue du PIB des États-Unis (1% de 25 billions de dollars américains) pour une modeste amélioration absolue de la précision de Tuvalu (190% de 66 millions de dollars américains). Le GPD des États-Unis est beaucoup plus important que celui de Tuvalu, mais on déciderait consciemment, et pour de bonnes raisons, de les traiter sur un pied d'égalité. Les États-Unis et Tuvalu peuvent être considérés comme "importants" dans le sens où l'on ne peut pas s'attendre à ce que les fluctuations statistiques ou la "malchance" soient responsables de l'erreur de prévision - c'est-à-dire que les déviations seront généralement statistiquement significatives et indiqueront un potentiel d'amélioration du modèle.
En résumé, lorsque des cas individuels de prévisions de valeurs différentes doivent être traités de la même manière, c'est-à-dire lorsque nous pouvons comparer des pommes énormes à des oranges minuscules, le MAPE peut s'avérer utile. Mais un traitement égal est-il toujours juste ?
Navigation stable dans toutes les conditions
Soyez prêt à tout avec la lettre d'information The Supply Chain Compass. Inscrivez-vous dès aujourd'hui pour recevoir chaque mois des informations sur les tendances mondiales et l'industrie.
Traiter tout le monde de la même manière - c'est une bonne chose en général, mais pas dans le cadre de l'évaluation des prévisions probabilistes.
Reprenons l'exemple de l'épicerie et parlons des pommes, des boîtes de thon et des bouteilles. Dans ce cas, la comparaison des APE n'a guère de sens, et ce pour deux raisons.
Par définition, un vendeur lent vend moins souvent qu'un vendeur rapide. L'impact commercial d'une prévision de vente lente peu fiable est donc beaucoup moins important que celui d'une prévision de vente rapide tout aussi peu fiable. Une perte de 5% due à une rupture de stock sur un produit marginal à faible rotation est simplement gênante pour le vendeur, alors qu'une perte de 5% sur le produit le plus vendu peut être tout à fait dramatique. En fin de compte, les chiffres absolus comptent pour votre entreprise. Vous avez surestimé la demande totale de votre produit principal aux États-Unis de 20%? Vous avez probablement un problème et devez gérer un grand nombre de stocks invendus, ce qui pourrait même mettre en péril l'ensemble de votre entreprise. Vous surestimez la demande totale de ce même produit de 20% à Tuvalu ? Rien contre Tuvalu (sans vouloir vous offenser !), mais vous pouvez probablement vous détendre, car cette erreur ne coulera pas votre entreprise. Vous pouvez tolérer une erreur relative beaucoup plus importante dans les petits assortiments ou marchés que dans vos catégories de pain & butter. Pourquoi accorder à des produits ou à des groupes de clients marginaux la même importance qu'aux vrais gros poissons ?
Outre cette différence évidente (petit est petit et grand est grand), il existe un effet statistique subtil mais important : la dépendance d'échelle de la précision des prévisions réalisables. Une erreur de 10% pour un produit qui se vend 10 fois par jour est parfois inévitable, même dans le cas d'une prévision parfaite (avec une incertitude de Poisson). Une réduction de 10% sur un produit qui se vend 10 000 fois par jour indique clairement qu'il y a un problème. Non seulement la vente lente est moins importante sur le plan commercial que la vente rapide, mais elle s'accompagne naturellement d'erreurs relatives plus importantes, comme nous l'avons expliqué plus en détail dans les articles précédents du blog Forecasting few is different, partie 1 et partie 2.
Pour les prévisions de l'épicerie ci-dessus, vous n'avez probablement pas eu de chance en ce qui concerne le thon ce jour-là. Les 16 bouteilles d'eau supplémentaires semblent moins excusables. Par conséquent, le pourcentage d'erreur absolue (PEA) ne rend pas bien compte de la qualité des prévisions réalisables, ni en termes commerciaux (il pondère de manière égale des éléments inégaux), ni en termes statistiques (sa valeur réalisable a besoin du contexte de la valeur prévue elle-même).
La gestion du réapprovisionnement par MAPE conduit à des niveaux de stocks catastrophiques
En d'autres termes, le MAPE n'est pas un bon indicateur de la qualité des prévisions en soi : Le fait que 20%, 70% et 90% soient atteints dans trois situations différentes n'a pas de signification interprétable immédiate. Compte tenu d'une certaine valeur MAPE, il ne faut pas tirer de conclusions hâtives. Même en admettant qu'une valeur MAPE ne vous dise rien ou presque sur la qualité globale de votre modèle, vous pouvez néanmoins vous attendre à ce que, pour une situation de prévision donnée, la prévision gagnante en termes de MAPE soit la meilleure. Comme je vais l'expliquer maintenant, vous devez également renoncer à cette attente plus faible.
Prenons l'exemple d'un supermarché qui propose de nombreux produits différents - des produits à rotation lente qui se vendent environ une fois par trimestre aux produits à rotation rapide qui se vendent 100 fois par jour. Le réapprovisionnement des articles est effectué par un système qui choisit la prévision optimale MAPE quotidienne et passe des commandes préalables en fonction de celle-ci. En d'autres termes, il choisit la valeur de la prévision pour laquelle le MAPE est le plus faible. Quels seraient les résultats de ce supermarché ?
Pour faire simple, concentrez-vous sur 5 produits exemplaires : les pommes, les bananes, les noix de cajou, les fruits du dragon et les aubergines : Pommes, bananes, noix de cajou, fruits du dragon et aubergines, avec des taux de vente quotidiens moyens réels de 0,01, 0,1, 1, 10 et 100 : le plus lent, les pommes, se vend environ une fois par trimestre, le plus rapide, les aubergines, se vend 100 fois par jour (vous avez raison si vous pensez que ces chiffres n'ont pas été inventés pour des raisons de plausibilité dans le monde réel, mais plutôt pour des raisons de clarté et de simplicité mathématique). Dans cette expérience de pensée, nous connaissons ces taux de vente et, par construction, ils constituent la meilleure prévision possible pour chaque produit. En utilisant la distribution de Poisson, nous pouvons simuler ce qui se passe et déterminer la valeur prévisionnelle ayant le meilleur MAPE.
Pour chaque produit, le tableau suivant indique le taux de vente réel (qui est la meilleure prévision journalière non biaisée), son MAPE simulé, la prévision optimisée gagnante du MAPE, son MAPE simulé et le biais qui en résulte :
Produit
Taux de vente journalier réel, prévisions journalières non biaisées
MAPE du taux de vente réel
Prévision journalière gagnante du MAPE
MAPE de la prévision gagnante MAPE
Biais de prévision de la prévision gagnante MAPE
Pommes
0.01
99%
1
0.25%
+9,900%
Bananes
0.1
90%
1
2.5%
+900%
Noix de cajou
1
23.3%
1
23.3%
0%
Fruits du dragon
10
31%
9
29%
-10%
Aubergines
100
8.11%
99
8.05%
-1%
Rappelez-vous que le taux de vente journalier réel est incontestablement la meilleure donnée d'entrée possible pour le système de réapprovisionnement, puisqu'il s'agit, par construction, de la valeur moyenne des ventes attendues. Que se passe-t-il si le réapprovisionnement utilise plutôt la prévision gagnante MAPE ? Le supermarché surstocke les produits à faible rotation : Chaque jour, une pomme, une banane et une noix de cajou sont réapprovisionnées - mais les pommes ne se vendent que tous les 100 jours et les bananes tous les 10 jours ! Les pommes et les bananes s'accumulent, les noix de cajou se portent bien, mais la demande de fruits du dragon n'est pas satisfaite : En moyenne, un client qui voulait acheter un fruit du dragon repart sans avoir terminé ses achats. Pour les aubergines qui évoluent rapidement, l'erreur de 1% peut être excusable - néanmoins, il est frappant de constater que la "meilleure" prévision est toujours biaisée, à moins que le véritable taux de vente ne soit égal à 1.
Les chiffres calculés pour le tableau ci-dessus supposent un monde parfait dans lequel les prévisionnistes aiment travailler avec un modèle présentant une incertitude de Poisson minimale. Pour un modèle plus réaliste dans lequel une incertitude supplémentaire modérée (techniquement parlant : surdispersion) est présente, la situation se dégrade immédiatement :
Produit
Taux de vente journalier réel, prévisions journalières non biaisées
MAPE du taux de vente réel
Prévision journalière gagnante du MAPE
MAPE de la prévision gagnante MAPE
Biais de prévision de la prévision gagnante MAPE
Pommes
0.01
99%
1
0.3%
+9,900%
Bananes
0.1
90%
1
3%
+900%
Noix de cajou
1
25%
1
25%
0%
Fruits du dragon
10
73%
6
53%
-40%
Aubergines
100
49%
72
40%
-28%
L'écart entre la valeur MAPE calculée au taux de vente réel et la valeur MAPE de la prévision gagnante MAPE s'est considérablement accru. En d'autres termes, l'utilisateur peut penser que la "preuve" que la prévision gagnante du MAPE est meilleure que l'autre est encore plus forte que précédemment. La prévision optimale MAPE est toutefois plus fortement biaisée que dans la situation idéale : La sous-estimation des fruits du dragon et des aubergines s'élève maintenant à 40% et 28%, respectivement - ce qui entraînerait une rupture de stock massive. Nous verrons ci-dessous pourquoi une plus grande incertitude signifie que nous devons jouer la carte de la sécurité et pourquoi cela signifie que nous devons jouer plutôt bas.
Il est évident qu'un supermarché qui applique cette stratégie ne survivra pas longtemps ! Les problèmes posés par le MAPE vont donc au-delà de l'interprétabilité commerciale (il n'est pas adapté pour répondre à la question "quelle est la qualité de la prévision ?"). mais peut potentiellement conduire à de graves problèmes opérationnels (choix d'une prévision incontestablement plus mauvaise qu'une meilleure). Voyons pourquoi !
MAPE censure les événements de comptage zéro, avec des conséquences catastrophiques
Lors du calcul de l'APE, nous rencontrons de sérieux problèmes lorsque la valeur réelle est nulle, car nous devons la diviser. L'APE est alors indéfini et n'entre pas dans le calcul du MAPE (rappelez-vous qu'il s'agit de la moyenne de tous les APE). En d'autres termes, les ventes nulles sont simplement supprimées des données. L'élimination de ces données est aussi mauvaise qu'elle en a l'air : Elle entraîne un biais de sur-prédiction flagrant sur les produits à rotation très lente (qui se vendent une fois ou moins par période de temps) dans une prédiction optimale MAPE : Puisque les événements 0 sont ignorés, la prédiction raisonnable la plus basse pour tout produit, lieu et jour est 1 - même pour un produit qui se vend une fois par an ! Étant donné que la prévision optimisée par le MAPE peut ignorer le résultat "0" en toute sécurité, il est prudent de proposer "1" comme valeur prévisionnelle la plus basse. Alternatives à l'enlèvement (par exemple L'attribution d'une erreur de 100% toujours au lieu de la suppression) ne résout pas ce problème : une prédiction de 1,7 avec l'issue 0 est clairement moins problématique qu'une prédiction de 17 000 avec l'issue 0 ; attribuer à ces deux événements le même APE artificiel n'a pas de sens. En d'autres termes, lorsque vos données peuvent contenir de manière plausible "0" comme valeur réelle pour tout événement, le MAPE est extrêmement problématique. L'optimiser conduira à des prévisions excessives pour les éléments qui se déplacent très lentement, comme nous le voyons dans les deux premières lignes des tableaux.
Le MAPE pénalise différemment les sous-estimations et les surestimations, ce qui conduit à des estimations biaisées.
Prévoir 1, observer 7 : l'APE est de 6/7, environ. 86%. Cela vous semble-t-il beaucoup ? Si c'est le cas, échangez les nombres, prédisez 7, observez 1 : Votre APE devient 6/1, 600%! L'APE pénalise beaucoup plus lourdement une surestimation d'un certain facteur qu'une sous-estimation du même facteur. Pour les prévisions insuffisantes, l'APE la plus défavorable est de 100%; pour les prévisions excessives, elle est illimitée. Par conséquent, lorsque vous n'êtes pas certain du résultat (vous ne devriez jamais l'être, et tout bon modèle connaît d'une certaine manière sa propre incertitude), jouer la sécurité, c'est jouer la faiblesse : Évitez à tout prix (ou presque) une forte surestimation, alors qu'une sous-estimation massive ne vous fera pas perdre la tête. Par conséquent, même dans le cas d'une incertitude minimale des prévisions, que nous avons supposé dans le premier tableau, la prévision optimale MAPE est une sous-estimation pour les taux de vente supérieurs à 1 (deux dernières lignes). En outre, plus la variabilité des données d'entraînement est importante, plus le modèle est incertain et plus la prévision optimale MAPE sera sous-estimée : Rappelez-vous que jouer la sécurité, c'est jouer la faiblesse, et que plus vous êtes incertain, plus vous voulez être sûr, et plus la prévision optimale MAPE devient faible. Cette couverture contre les surprédictions entraîne un biais important dans les deux dernières lignes du deuxième tableau. Cette asymétrie est traitée par des MAPE modifiés : Par exemple, le pourcentage d'erreur peut être calculé par rapport à la moyenne de la prédiction et de la réalité au lieu de la seule réalité - mais ces modifications ne résolvent pas complètement l'asymétrie et induisent d'autres problèmes et paradoxes.
Le MAPE présente un comportement d'échelle particulièrement complexe, ce qui nous laisse dans l'ignorance quant à la qualité réelle d'une prévision.
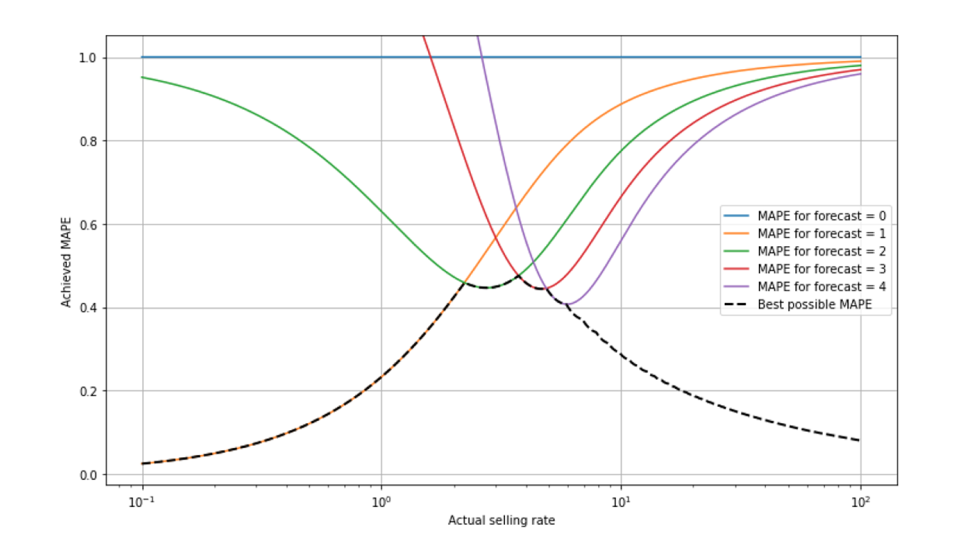
Certes, le manque d'interprétabilité (est-ce que 50% MAPE est bon ou mauvais ?) n'est pas une caractéristique exclusive du MAPE : Chaque mesure est dépendante de l'échelle et prend des valeurs différentes selon qu'il s'agit d'un changement lent ou rapide. Néanmoins, l'échelle du MAPE est particulièrement complexe, en raison de la combinaison des deux effets susmentionnés : D'une part, une prévision MAPE optimale ne produira jamais un nombre inférieur à 1 et nous éliminons simplement les résultats de vente nuls. En revanche, les erreurs relatives diminuent pour les taux de vente élevés. Dans ce graphique, nous montrons le "MAPE de montage", c'est-à-dire le meilleur MAPE possible en fonction du taux de vente.
Respirez profondément et laissez-moi vous expliquer ce que vous voyez : L'échelle x est logarithmique, ce qui nous permet d'observer les petits taux de vente - l'échelle va de 0,1 à 100, de très lent à rapide. Pour les petits taux de vente inférieurs à environ 2, une prévision de 1 est la meilleure possible, elle donne la valeur MAPE donnée par la ligne orange qui va de la partie inférieure gauche (où elle est recouverte par la ligne noire en pointillés) à la partie supérieure droite. La prévision 2 conduirait à un MAPE élevé chez les slow-movers (ligne verte), proche de 95% pour un taux de vente de 0,1. La prévision 0 conduit toujours à un MAPE constant de 100% (ligne bleue) : Pour tout résultat qui n'est pas 0 (et ceux-là sont retirés de l'évaluation), nous avons APE=|actuel-0|/actuel=100%. À un taux de vente d'environ 2,3, la prévision 2 devient optimale, ce qui explique que la ligne noire en pointillés, qui représente le meilleur MAPE possible, passe de la ligne orange à la ligne verte. En outre, elle se relaie chaque fois que la meilleure prévision passe d'une valeur à l'autre (les prévisions 3 et 4 sont représentées respectivement en rouge et en violet).
Le meilleur MAPE possible diminue lorsque l'on passe à des articles qui se vendent très lentement (à gauche) : Étant donné que les événements à 0 vente sont supprimés des données, les événements "survivants" sont pour la plupart des événements à 1 vente, et ce d'autant plus que l'article se vend lentement. Pour un taux de vente de 0,1, l'observation de 2 articles vendus le même jour est déjà très improbable, et la prévision "1" est donc, dans la plupart des cas autres que 0, parfaite, et le MAPE obtenu assez faible. En d'autres termes, si vous savez que "0" sera supprimé des données et que l'article est lent, alors "1" est une valeur sûre pour le nombre de ventes réalisées. Pour les valeurs moyennes autour de 1 à 5, nous voyons le "virage" de la meilleure MAPE possible. Pour les prévisions importantes de 10 ou plus (à droite du graphique), le MAPE réalisable diminue à nouveau : la distribution de Poisson devient relativement étroite dans la limite des taux importants (voir notre précédent article de blog sur Forecasting Few is Different 1 &2).
J'ai vraiment fait de mon mieux pour expliquer la forme de "mount MAPE" ! Il m'a fallu plus de 300 mots en deux paragraphes, mais je crains que ce ne soit pas tout à fait réussi : L'avez-vous compris de manière à pouvoir juger intuitivement les MAPE à l'avenir, dans le contexte des taux de vente prévus ? Si vous ne le pensez pas, ne vous inquiétez pas : cette complexité est un autre argument modeste qui montre que, même parmi les professionnels, il est peu probable qu'un jugement intuitif correct des valeurs MAPE devienne un jour largement répandu.
Les prévisions optimales MAPE ne sont pas pertinentes pour l'entreprise, ce qui compromet la valeur potentielle des prévisions.
La prévision qui gagne en MAPE n'est pas la prévision non biaisée que vous souhaiteriez dans de nombreuses applications. Mais que signifie alors "optimiser pour le MAPE" ? Mathématiquement, la valeur qui minimise le MAPE minimise une expression encombrante que je n'ose même pas écrire dans un article de blog qui ne s'adresse pas aux statisticiens. Ce que vous devez savoir : Cette expression n'a pas d'interprétation commerciale significative. Quel que soit l'objectif que vous poursuivez avec vos prévisions - assurer la disponibilité, réduire les déchets, planifier les promotions et les démarques, réapprovisionner les articles, planifier la main-d'œuvre... - le coût commercial d'une prévision erronée dans votre application n'est certainement pas reflété par le MAPE ! Idéalement, choisissez une mesure d'évaluation qui reflète le coût financier réel d'une prévision erronée. Vous ne voulez pas optimiser une fonction mathématique abstraite, mais maximiser la valeur de l'entreprise.
L'alternative : Laisser l'indicateur refléter directement l'activité de l'entreprise
En dehors de situations telles que la prévision des PIB par pays et sous des hypothèses fortes, le MAPE n'est pas adapté pour indiquer la qualité d'un modèle de prévision (en raison de la mise à l'échelle), ni un facteur de décision approprié pour choisir entre deux modèles concurrents (les prévisions gagnantes du MAPE sont biaisées). Quelle est l'alternative ? Dans le meilleur des cas, la mesure utilisée reflète directement la valeur de l'entreprise. L'erreur absolue moyenne (MAE) quantifie les situations dans lesquelles le coût d'un article surstocké est identique au coût d'un article manquant - une hypothèse forte, mais certainement plus proche de la réalité que le MAPE. L'EAM comporte la même dimension que la prédiction elle-même ("nombre d'éléments") et dépend donc fortement de l'échelle. En divisant l'EAM par les ventes moyennes, on obtient l'erreur absolue moyenne relative (EAMR) qui, en raison de la propriété d'échelle de la distribution de Poisson, n'est pas non plus indépendante de l'échelle. La dépendance d'échelle doit donc toujours être abordée de manière explicite.
Cependant, il n'est pas possible d'ignorer que les estimations optimales du MAPE sont biaisées : Des décisions stratégiques importantes dépendent d'une évaluation fiable, significative et pertinente des prévisions ! Devons-nous choisir le fournisseur de logiciels A, le fournisseur de logiciels B ou notre solution interne ? Sur quels assortiments devons-nous concentrer nos efforts d'amélioration des modèles ? Les prévisions de cette nouvelle catégorie sont-elles "suffisamment bonnes" pour qu'un système automatisé soit mis en place ? L'évaluation des prévisions doit fournir des éléments clairs, interprétables à haut niveau et reflétant la réalité de l'entreprise pour répondre à ces questions et à bien d'autres encore. La MAPE ne peut pas nous aider à cet égard.
Votre erreur absolue moyenne (MAE) vous donne-t-elle des mesures de performance incomplètes ? Découvrez pourquoi l'évaluation des modèles doit être corrigée et quelles sont les étapes fondamentales pour une meilleure évaluation des modèles.