
















On a beaucoup parlé de la façon dont l'IA générative va changer le travail dans la chaîne d'approvisionnement. Chez Blue Yonder, nous avons voulu examiner ces impacts par le biais d'une étude comparative. Dans notre expérience de recherche, nous avons exploré les capacités des grands modèles de langage (LLM) et nous avons cherché à savoir s'ils pouvaient être appliqués efficacement à l'analyse de la chaîne d'approvisionnement pour résoudre les problèmes réels rencontrés dans la gestion de la chaîne d'approvisionnement.
Les LLM, dont ChatGPT, sont un type d'intelligence artificielle formée sur des quantités massives de données, ce qui leur permet d'apprendre les modèles, la grammaire et la sémantique de la langue. Ces dernières années, les masters en droit ont connu une croissance fulgurante et sont utilisés dans toute une série d'applications dans le monde entier, notamment la création de contenu, le service à la clientèle et les études de marché.
Les données d'IDC révèlent que les secteurs des logiciels et des services d'information, de la banque et du commerce de détail devraient consacrer environ 89,6 milliards de dollars à l'IA en 2024, l'IA générative représentant plus de 19% de l'investissement total.
Cette technologie en évolution rapide offre aux entreprises une créativité, une efficacité et des capacités de prise de décision accrues, qui ont le pouvoir de révolutionner les industries et les processus. Comment les gestionnaires du droit d'auteur gèrent-ils actuellement les situations liées à la chaîne d'approvisionnement ?
À propos de l'étude comparative de Blue Yonder sur l'IA générative
Notre test d'IA générative sur la chaîne d'approvisionnement s'inspire vaguement de l'expérience virale ChatGPT appelée "Uniform Bar Examination". Dans cette étude, la dernière version de ChatGBT a réussi l'examen du barreau avec un score combiné élevé de 297, approchant le 90e percentile de tous les participants au test. En passant le barreau avec un score proche du top 10 sur%, les LLM démontrent la capacité de l'IA générative à comprendre et à appliquer les principes et les réglementations juridiques. Cette étude révolutionnaire a suscité un débat mondial et mis en lumière le potentiel de transformation de l'IA.
Blue Yonder a décidé d'aller plus loin en étudiant les résultats des principaux systèmes de LLM aux examens de l'industrie de la chaîne d'approvisionnement. Nous avons confronté les LLM à deux tests de certification standard, le CPSM et le CSCP. Notre objectif ? Vérifier si les titulaires d'une maîtrise en droit peuvent fonctionner comme des professionnels de la chaîne d'approvisionnement, en comprenant les règles de niche et le contexte de l'industrie de la chaîne d'approvisionnement sans avoir suivi de formation.
Nous avons conçu l'expérience de manière à ce que chaque MLD passe les tests pratiques de manière programmée, sans contexte autour du test, sans accès à l'internet et sans capacité de codage. Nous voulions évaluer les performances des LLM dès leur sortie de l'emballage, afin d'obtenir une évaluation cohérente et impartiale.
Les tests de certification CPSM et CSCP sont tous deux à choix multiples. Plutôt que de laisser les LLM sélectionner simplement une réponse, nous avons mis en place une sortie pour les modèles afin d'expliquer chaque choix qu'ils ont sélectionné. Cette approche nous a permis d'obtenir des informations précieuses sur le processus de raisonnement de chaque modèle et de comprendre pourquoi il obtenait des réponses erronées ou correctes, ce qui nous a aidés à évaluer les capacités de chaque modèle.
Après la publication des versions actualisées des LLM, nous avons refait le test cet été afin de recueillir de nouveaux résultats de référence.
Les titulaires d'une maîtrise en droit peuvent-ils réussir les examens relatifs à la chaîne d'approvisionnement ?
Il est impressionnant de constater que les titulaires d'une maîtrise en droit ont obtenu des résultats surprenants aux examens portant sur la chaîne d'approvisionnement, et ce sans aucune formation. Nous avons d'abord examiné les performances des LLM sans contexte, puis nous avons ajouté certains avantages.
Étape 1 : Pas de contexte, pas d'accès à l'internet, pas de capacité de codage
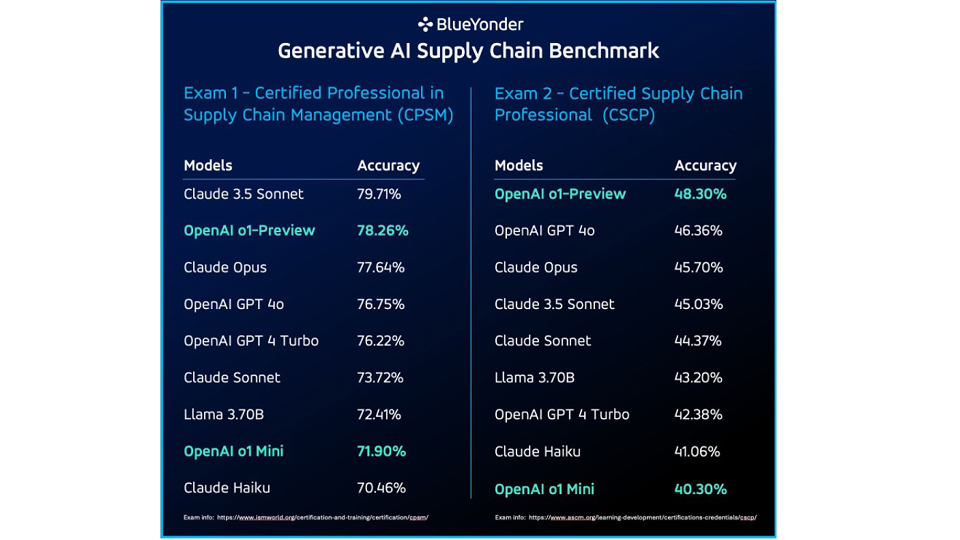
Alors que la plupart des modèles ont obtenu la note de passage sans contexte, Claude 3.5 Sonnet s'est distingué en obtenant une précision impressionnante de 79,71% lors du test de certification du CPSM. Lors de l'examen CSCP, les modèles o1-Preview et GPT 4o d'OpenAI ont devancé Claude Opus, avec une précision de 48,30% contre 45,7% pour ce dernier.
Si les LLM ont obtenu de bons résultats dans certains domaines, ils ont également montré des limites, en particulier lorsqu'ils ont été confrontés à des questions liées aux mathématiques ou à des questions très spécifiques à un domaine.
En examinant uniquement les problèmes mathématiques de chaque examen de certification, OpenAI o1 Mini a montré une amélioration significative de la précision des modèles OpenAI, surpassant les modèles Claude testés.

Ces résultats ont été générés sans contexte, sans accès à Internet et sans capacité de codage. Ensuite, nous avons examiné ce qui se passerait si nous commencions à apporter plus d'aide aux gestionnaires de l'éducation et de la formation tout au long de la vie.
Étape 2 : Ajout d'un accès à l'internet
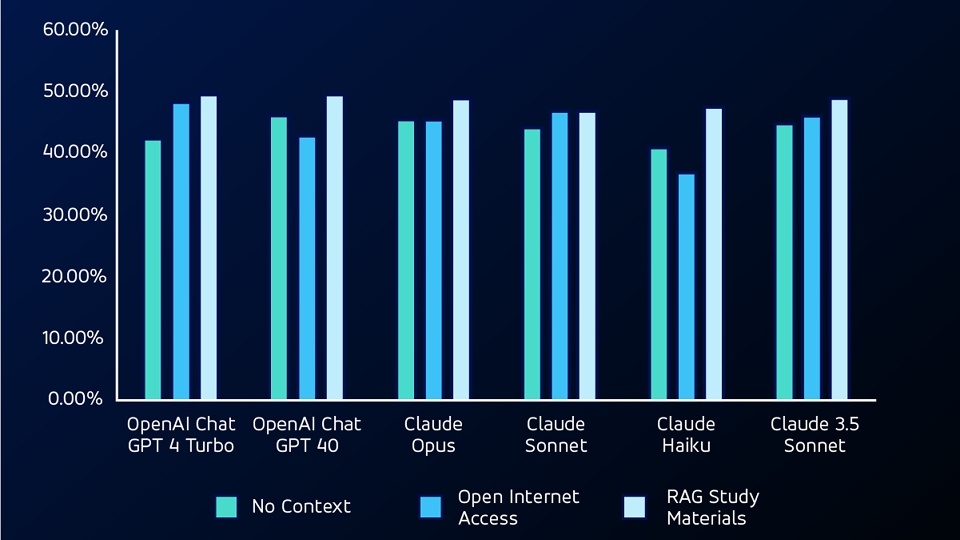
Lors de l'étape suivante du test, nous avons donné aux programmes LLM l'accès à l'internet, ce qui leur a permis d'effectuer des recherches sur you.com. Avec cette capacité supplémentaire, OpenAI GPT 4 Turbo a réalisé l'avancée la plus significative - de 42,38% à 48,34% - sur le test CSCP.
Si l'on considère les questions qui ont été initialement omises lors du premier test sans contexte, le modèle de Claude Sonnet a obtenu un taux de précision d'environ 53,84% pour les questions du CPSM et de 20% pour les questions du CSCP.
Si l'accès à Internet a permis aux modèles de rechercher des informations de manière indépendante, il a également introduit le risque d'inexactitudes dues à des sources d'information en ligne peu fiables.
Étape 3 : Mise en contexte avec le RAG
Pour le test suivant, nous avons utilisé un modèle RAG (retrieval augmented generation), en fournissant aux LLM le matériel d'étude des tests. En utilisant RAG, le LLMS a surpassé à la fois les tests sans contexte et les tests d'accès ouvert à l'Internet pour les questions non mathématiques, obtenant les scores de précision les plus élevés pour les deux tests.
Étape 4 : Ajouter des capacités de codage
Enfin, pour le test suivant, nous avons donné aux modèles la possibilité d'écrire et d'exécuter leur propre code en utilisant les cadres Code Interpreter et Open Interpreter.
En utilisant ces cadres, les LLM ont pu écrire du code pour aider à résoudre les questions mathématiques des examens, avec lesquelles ils ont eu des difficultés lors de la première itération de l'examen. Avec les capacités de codage, les LLM ont surpassé le test sans contexte d'une moyenne d'environ 28% en termes de précision sur tous les modèles pour les questions mathématiques.
Les masters en droit sont-ils utiles pour résoudre les problèmes liés à la chaîne d'approvisionnement ?
Dans l'ensemble, les systèmes LLM ont réussi les examens de la chaîne d'approvisionnement standard de l'industrie. Cette performance offre une possibilité très intéressante d'intégrer les LLM dans la gestion de la chaîne d'approvisionnement. Cependant, les modèles ne sont pas encore parfaits. Ils se sont heurtés à des problèmes mathématiques et à la logique spécifique de la chaîne d'approvisionnement.
Avec la capacité supplémentaire d'écrire du code, les LLM ont pu surmonter de nombreux problèmes mathématiques, mais ils avaient encore besoin d'un contexte très spécifique à la chaîne d'approvisionnement pour résoudre certaines des questions les plus complexes de l'examen.
Ce que notre étude a révélé, c'est que l'IA générative peut être extrêmement utile pour résoudre les problèmes de la chaîne d'approvisionnement, avec les bons outils et la bonne formation.
Heureusement, c'est ce à quoi Blue Yonder excelle. Nous nous engageons à exploiter la puissance de l'IA générative pour créer des solutions pratiques et innovantes aux défis de la chaîne d'approvisionnement. Notre nouveau studio d'innovation en matière d'IA est un centre de développement de ces solutions, qui comble le fossé entre les technologies d'IA complexes et les applications du monde réel.
Nous nous concentrons sur la création d'agents intelligents adaptés à des rôles spécifiques au sein de la chaîne d'approvisionnement, en veillant à ce que ces agents soient équipés pour résoudre les problèmes et les défis réels et authentiques auxquels ils sont confrontés aujourd'hui. Apprenez-en plus sur l'IA et l'apprentissage automatique chez Blue Yonder, ou contactez-nous pour entamer une conversation individuelle.
